Abstract
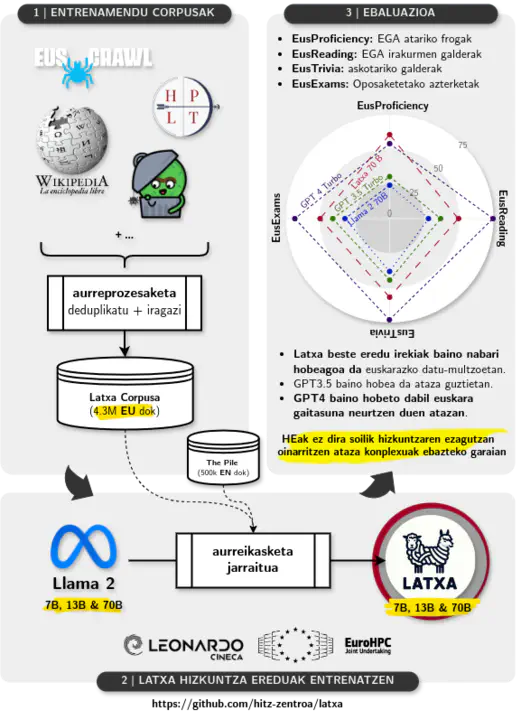
Artikulu honetan Latxa hizkuntza-ereduak (HE) aurkeztuko ditugu, egun euskararako garatu diren HE handienak. Latxa HEek 7.000 miloi parametrotik 70.000 milioira bitartean dituzte, eta ingeleseko LLama 2 ereduetatik eratorriak dira. Horretarako, LLama 2 gainean aurreikasketa jarraitua izeneko prozesua gauzatu da, 4.3 milioi dokumentu eta 4.200 milioi token duen euskarazko corpusa erabiliz. Euskararentzat kalitate handiko ebaluazio multzoen urritasunari aurre egiteko, lau ebaluazio multzo berri bildu ditugu: EusProficiency, EGA azterketaren atariko frogako 5.169 galdera biltzen dituena; EusReading, irakurketaren ulermeneko 352 galdera biltzen dituena; EusTrivia, 5 arlotako ezagutza orokorreko 1.715 galdera biltzen dituena; eta EusExams, oposizioetako 16.774 galdera biltzen dituena. Datu-multzo berri hauek erabiliz, Latxa eta beste euskarazko HEak ebaluatu ditugu (elebakar zein eleanitzak), eta esperimentuek erakusten dute Latxak aurreko eredu ireki guztiak gainditzen dituela. Halaber, GPT-4 Turbo HE komertzialarekiko emaitza konpetitiboak lortzen ditu Latxak, hizkuntza-ezagutzan eta ulermenean, testu-irakurmenean zein ezagutza intentsiboa eskatzen duten atazetan atzeratuta egon arren. Bai Latxa ereduen familia, baita gure corpus eta ebaluazio-datu berriak ere lizentzia irekien pean daude publiko https://github. com/hitz-zentroa/latxa helbidean.
Julen Etxaniz
PhD Student in Language Analysis and Processing
PhD Student in Language Analysis and Processing at Hitz Center IXA Group UPV/EHU. Working on Improving Language Models for Low-resource Languages. Graduate in Informatics Engineering with speciality in Software Engineering. Master in Language Analysis and Processing.