BabyBabelLM: A Multilingual Benchmark of Developmentally Plausible Training Data
Oct 11, 2025·,,,,,,,,,,,·
0 min read
Jaap Jumelet
Abdellah Fourtassi
Akari Haga
Bastian Bunzeck
Bhargav Shandilya
Diana Galvan-Sosa
Faiz Ghifari Haznitrama
Francesca Padovani
Francois Meyer
Hai Hu
Julen Etxaniz
others
Abstract
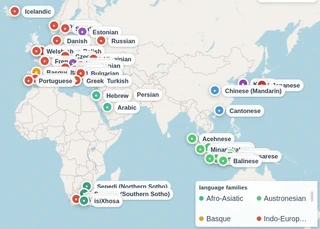
We present BabyBabelLM, a multilingual collection of datasets modeling the language a person observes from birth until they acquire a native language. We curate developmentally plausible pretraining data aiming to cover the equivalent of 100M English words of content in each of 45 languages. We compile evaluation suites and train baseline models in each language. BabyBabelLM aims to facilitate multilingual pretraining and cognitive modeling.
Type
Publication
EACL 2026