Large Language Models

The general objective of the IKER-GAITU project is to research on language technology to increase the presence of Basque in the digital environment. It will be carried out between 2023 and 2025 thanks to a grant from the Department of Culture and Language Policy of the Basque Government. Current techniques require enormous amounts of textual and oral data per language. On the other hand, the data available for Basque and other low-resource languages might not be enough to attain the same quality as larger languages with the current technology. For this reason, it is essential to research on language technology, so that low-resource languages are present with the same quality as the rest of the languages in these technologies. IKER-GAITU pursues the following research objectives: 1. A system that automatically captures the level of Basque proficiency, written and oral; 2. Bring personalized voice technology to people with disabilities; 3. Spontaneous voice transcription, both when Basque and Spanish are mixed and when there are several speakers; 4. Textual conversational systems in Basque that match the quality of the most powerful large language models. In this project summary we present the results for the first year. More information at https://hitz.eus/iker-gaitu.

XNLI is a popular Natural Language Inference (NLI) benchmark widely used to evaluate cross-lingual Natural Language Understanding (NLU) capabilities across languages. In this paper, we expand XNLI to include Basque, a low-resource language that can greatly benefit from transfer-learning approaches. The new dataset, dubbed XNLIeu, has been developed by first machine-translating the English XNLI corpus into Basque, followed by a manual post-edition step. We have conducted a series of experiments using mono- and multilingual LLMs to assess a) the effect of professional post-edition on the MT system; b) the best cross-lingual strategy for NLI in Basque; and c) whether the choice of the best cross-lingual strategy is influenced by the fact that the dataset is built by translation. The results show that post-edition is necessary and that the translate-train cross-lingual strategy obtains better results overall, although the gain is lower when tested in a dataset that has been built natively from scratch. Our code and datasets are publicly available under open licenses at https://github.com/hitz-zentroa/xnli-eu.

We introduce Latxa, a family of large language models for Basque ranging from 7 to 70 billion parameters. Latxa is based on Llama 2, which we continue pretraining on a new Basque corpus comprising 4.3M documents and 4.2B tokens. Addressing the scarcity of high-quality benchmarks for Basque, we further introduce 4 multiple choice evaluation datasets: EusProficiency, comprising 5,169 questions from official language proficiency exams; EusReading, comprising 352 reading comprehension questions; EusTrivia, comprising 1,715 trivia questions from 5 knowledge areas; and EusExams, comprising 16,774 questions from public examinations. In our extensive evaluation, Latxa outperforms all previous open models we compare to by a large margin. In addition, it is competitive with GPT-4 Turbo in language proficiency and understanding, despite lagging behind in reading comprehension and knowledge-intensive tasks. Both the Latxa family of models, as well as our new pretraining corpora and evaluation datasets, are publicly available under open licenses at https://github.com/hitz-zentroa/latxa. Our suite enables reproducible research on methods to build LLMs for low-resource languages.
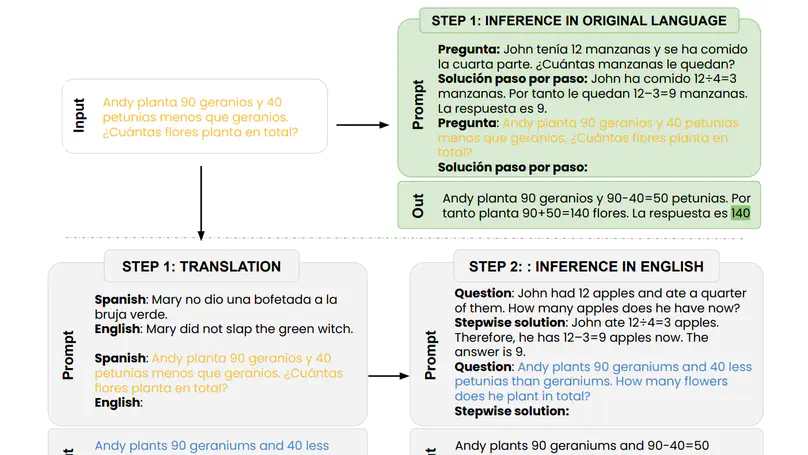
Translate-test is a popular technique to improve the performance of multilingual language models. This approach works by translating the input into English using an external machine translation system, and running inference over the translated input. However, these improvements can be attributed to the use of a separate translation system, which is typically trained on large amounts of parallel data not seen by the language model. In this work, we introduce a new approach called self-translate, which overcomes the need of an external translation system by leveraging the few-shot translation capabilities of multilingual language models. Experiments over 5 tasks show that self-translate consistently outperforms direct inference, demonstrating that language models are unable to leverage their full multilingual potential when prompted in non-English languages. Our code is available at https://github.com/juletx/self-translate.