Natural Language Processing
Large Language Models
Deep Learning
Evaluation
Commonsense Reasoning
Italian
Challenging the Abilities of Large Language Models in Italian: a Community Initiative
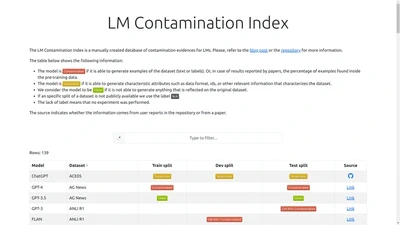
The rapid progress of Large Language Models (LLMs) has transformed natural language processing and broadened its impact across research and society. Yet, systematic evaluation of …