Corpus Linguistics
 Corpus Linguistics
Corpus LinguisticsJulen Etxaniz
Estudiante de Doctorado en Análisis y Procesamiento del Lenguaje
Estudiante de Doctorado en Análisis y Procesamiento del Lenguaje en HiTZ Center IXA Group (UPV/EHU). Trabajando en mejorar los modelos de lenguaje para idiomas con pocos recursos. Graduado en Ingeniería Informática con especialidad en Ingeniería del Software. Máster en Análisis y Procesamiento del Lenguaje.
Relacionado
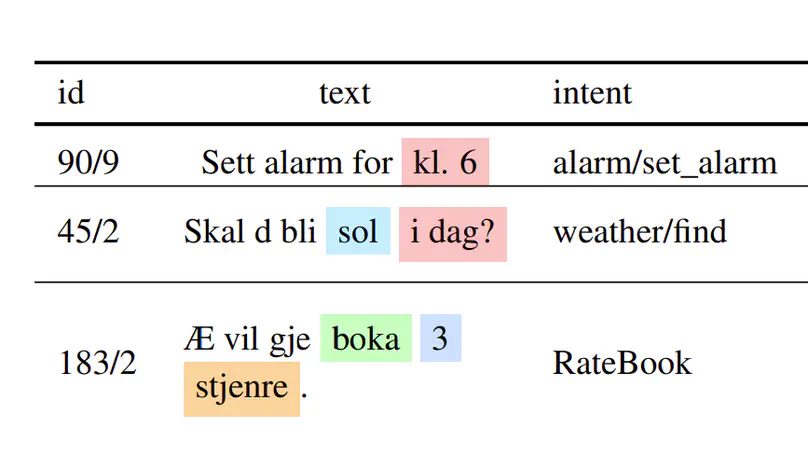

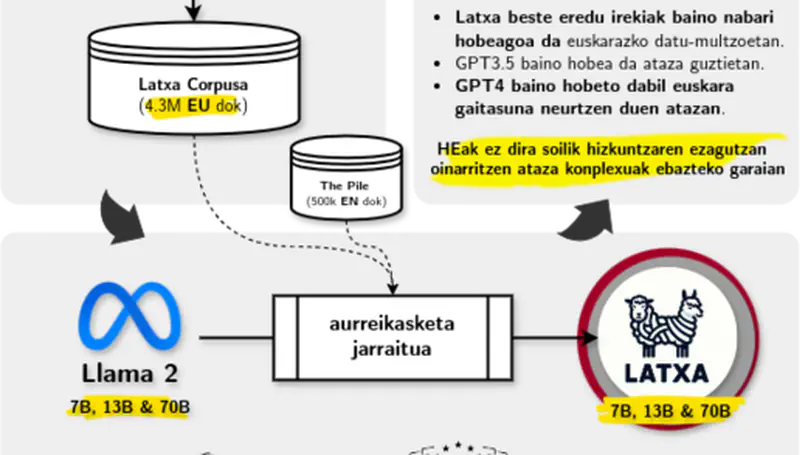

Large Language Models (LLMs) exhibit extensive knowledge about the world, but most evaluations have been limited to global or anglocentric subjects. This raises the question of how well these models perform on topics relevant to other cultures, whose presence on the web is not that prominent. To address this gap, we introduce BertaQA, a multiple-choice trivia dataset that is parallel in English and Basque. The dataset consists of a local subset with questions pertinent to the Basque culture, and a global subset with questions of broader interest. We find that state-of-the-art LLMs struggle with local cultural knowledge, even as they excel on global topics. However, we show that continued pre-training in Basque significantly improves the models’ performance on Basque culture, even when queried in English. To our knowledge, this is the first solid evidence of knowledge transfer from a low-resource to a high-resource language. Our analysis sheds light on the complex interplay between language and knowledge, and reveals that some prior findings do not fully hold when reassessed on local topics. Our dataset and evaluation code are available under open licenses at https://github.com/juletx/BertaQA.