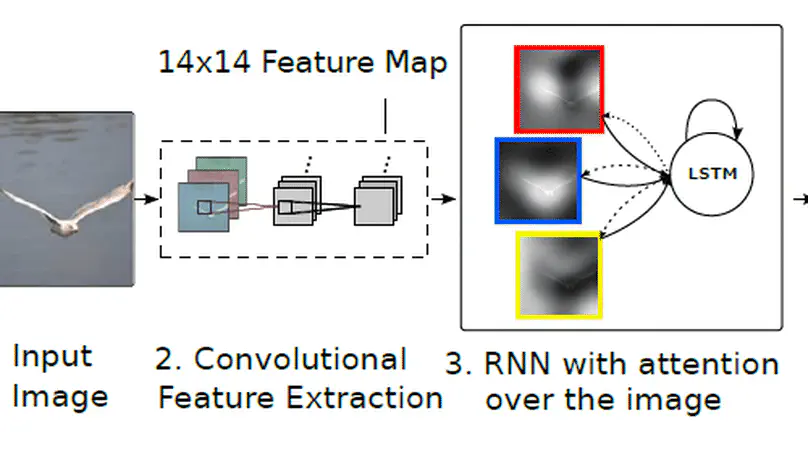
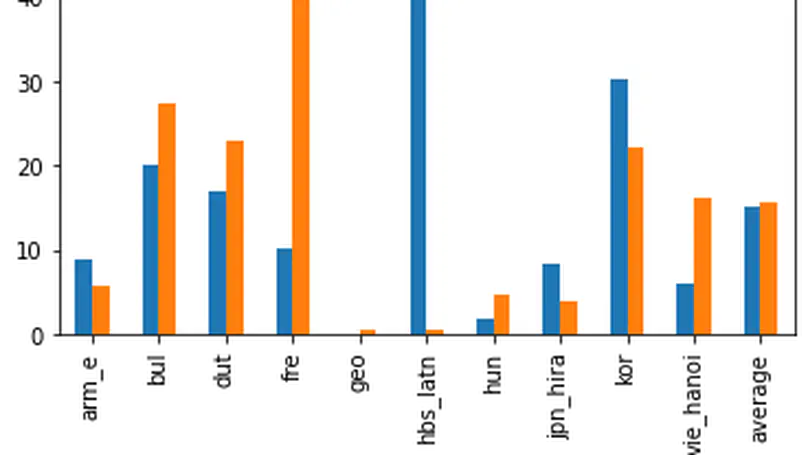
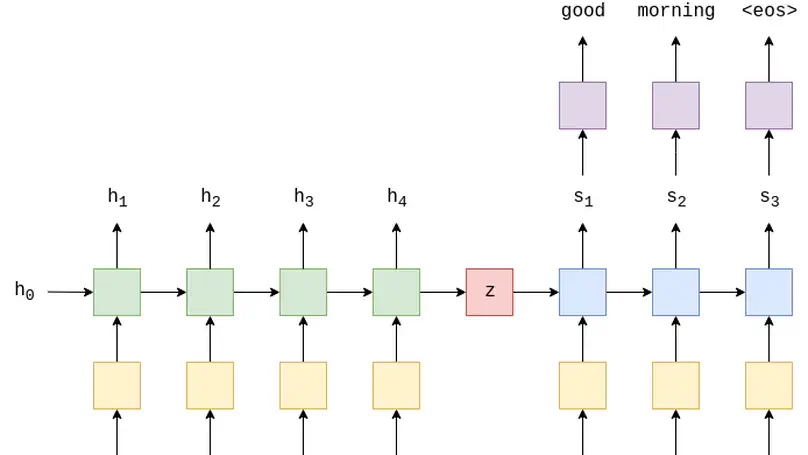
Deep Learning for Natural Language Processing
 Deep Learning for Natural Language Processing
Deep Learning for Natural Language ProcessingJulen Etxaniz
Estudiante de Doctorado en Análisis y Procesamiento del Lenguaje
Estudiante de Doctorado en Análisis y Procesamiento del Lenguaje en la Facultad de Informática de la Universidad del País Vasco (UPV/EHU). Graduado en Ingeniería Informática con especialidad en Ingeniería del Software.