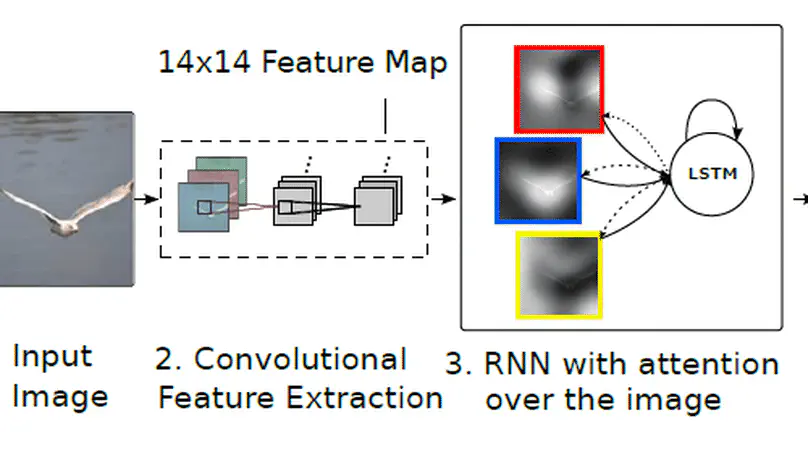
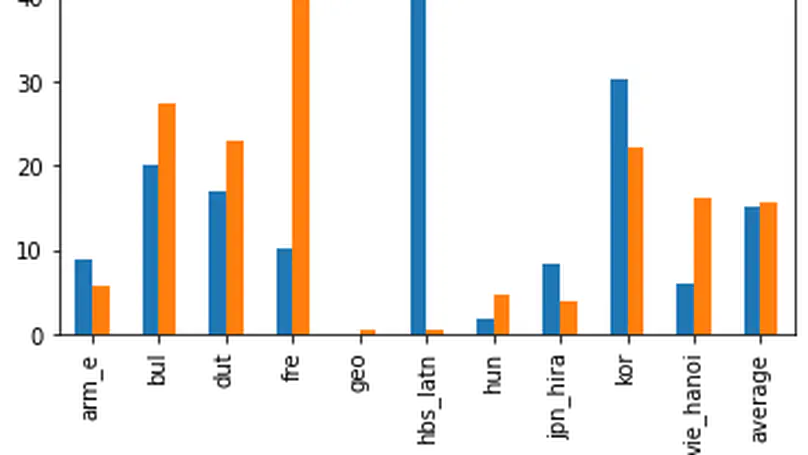
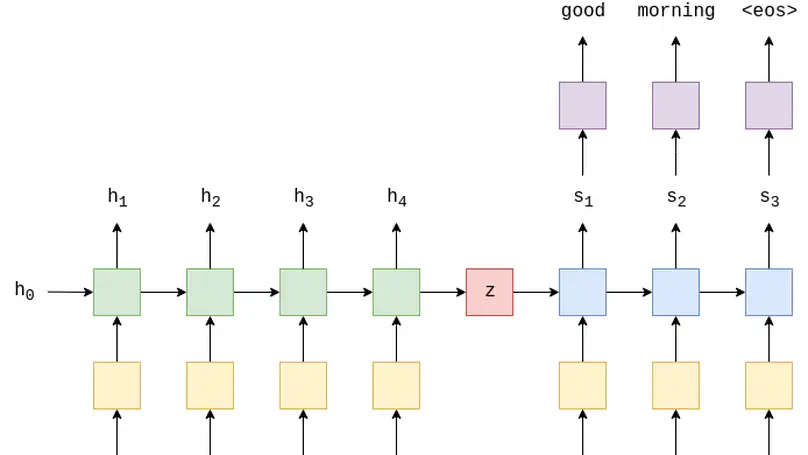
Zero-shot and Translation Experiments on XQuAD, MLQA and TyDiQA
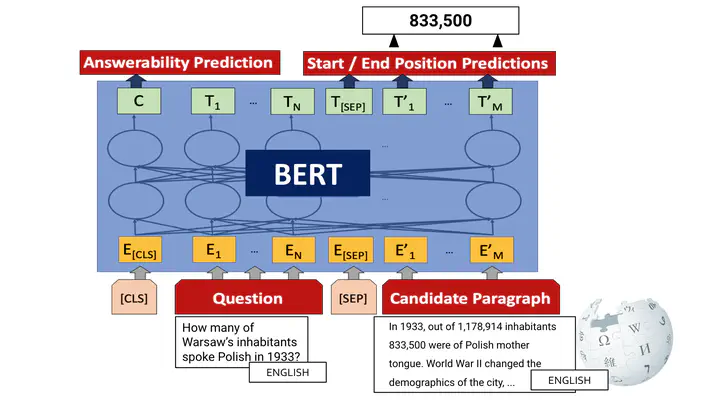 Zero-shot and Translation Experiments on XQuAD, MLQA and TyDiQA
Zero-shot and Translation Experiments on XQuAD, MLQA and TyDiQAJulen Etxaniz
Estudiante de Doctorado en Análisis y Procesamiento del Lenguaje
Estudiante de Doctorado en Análisis y Procesamiento del Lenguaje en HiTZ Center IXA Group (UPV/EHU). Trabajando en mejorar los modelos de lenguaje para idiomas con pocos recursos. Graduado en Ingeniería Informática con especialidad en Ingeniería del Software. Máster en Análisis y Procesamiento del Lenguaje.