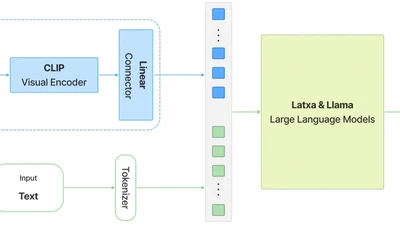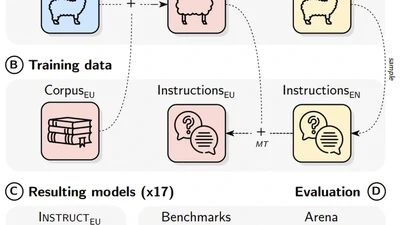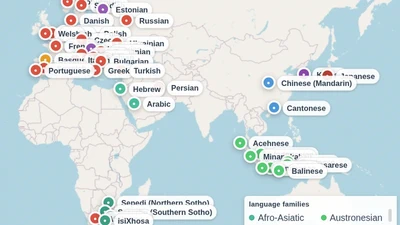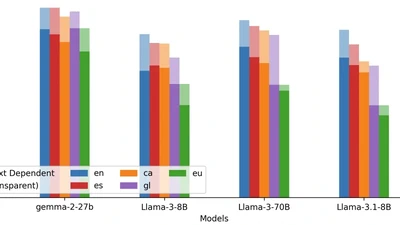
Natural Language Processing
Large Language Models
Deep Learning
Evaluation
Multilinguality
Basque
Linguistic Diversity
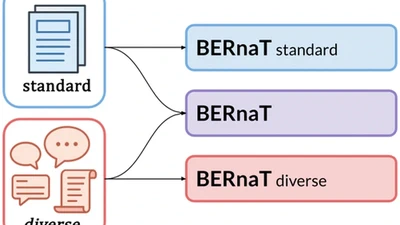
BERnaT: Basque Encoders for Representing Natural Textual Diversity
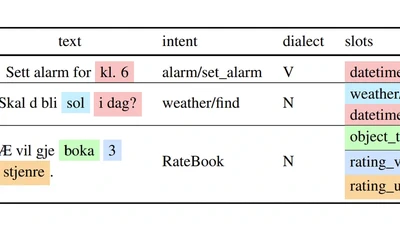
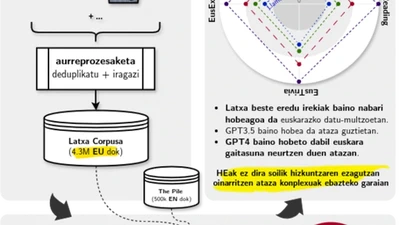
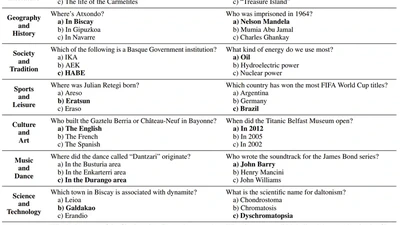
Language models depend on massive text corpora that are often filtered for quality, a process that can unintentionally exclude non-standard linguistic varieties, reduce model …