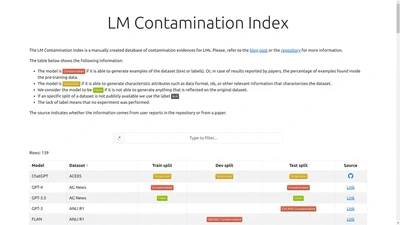
NLP Evaluation in trouble: On the Need to Measure LLM Data Contamination for each Benchmark
In this position paper, we argue that the classical evaluation on Natural Language Processing (NLP) tasks using annotated benchmarks is in trouble. The worst kind of data …
EMNLP 2023 Findings
Oscar Sainz
Jon Ander Campos
Iker García-Ferrero
Julen Etxaniz
Oier Lopez de Lacalle
Eneko Agirre