Grounding Language Models for Spatial Reasoning
 Grounding Language Models for Spatial Reasoning
Grounding Language Models for Spatial ReasoningJulen Etxaniz
PhD Student in Language Analysis and Processing
PhD Student in Language Analysis and Processing at Hitz Center IXA Group UPV/EHU. Working on Improving Language Models for Low-resource Languages. Graduate in Informatics Engineering with speciality in Software Engineering. Master in Language Analysis and Processing.
Related

Publications

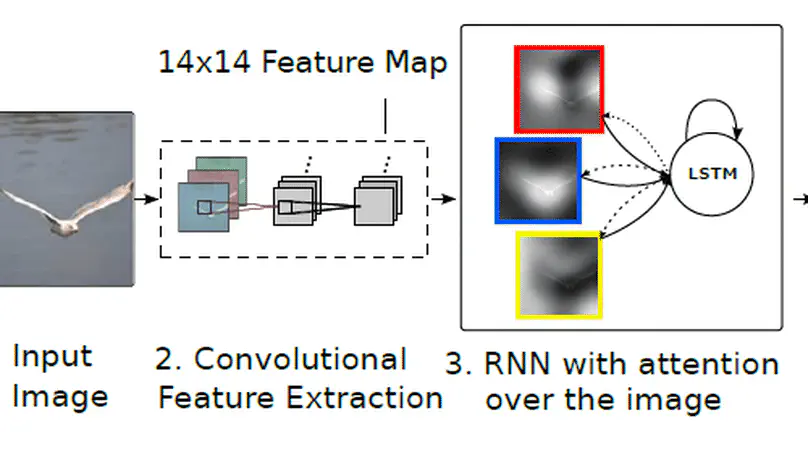
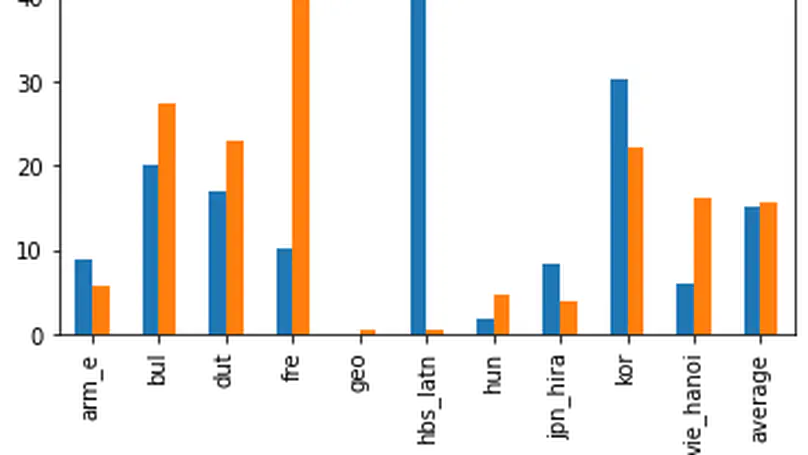
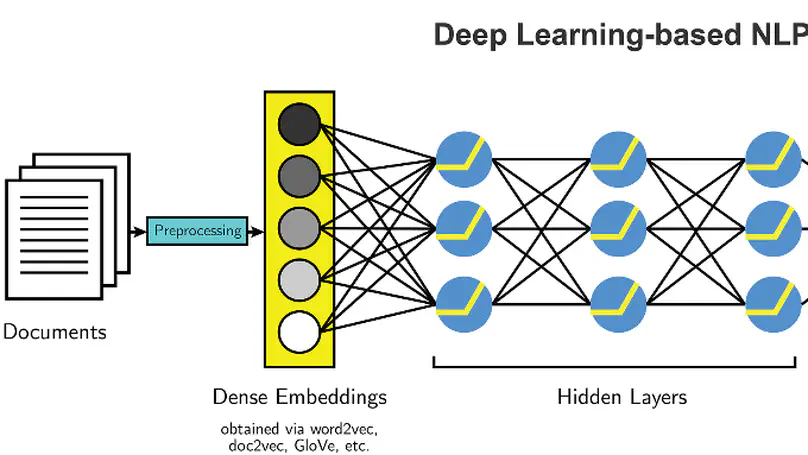
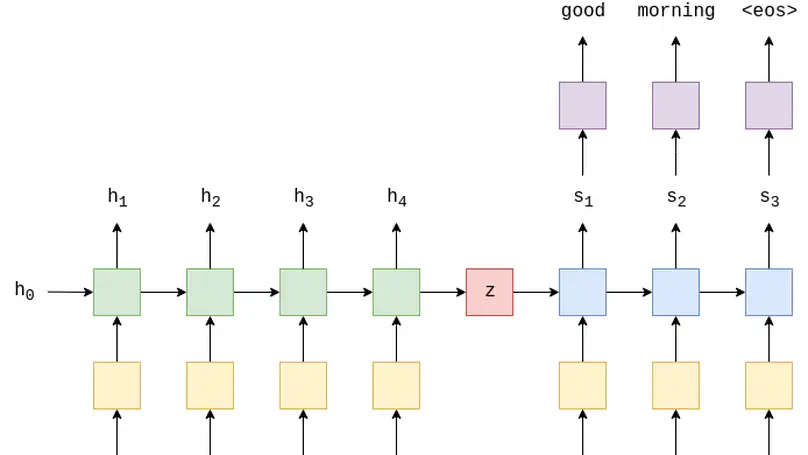
Humans can learn to understand and process the distribution of space, and one of the initial tasks of Artificial Intelligence has been to show machines the relationships between space and the objects that appear in it. Humans naturally combine vision and textual information to acquire compositional and spatial relationships among objects, and when reading a text, we are able to mentally depict the spatial relationships that may appear in it. Thus, the visual differences between images depicting "a person sits and a dog stands" and "a person stands and a dog sits" are obvious for humans, but still not clear for automatic systems. In this project, we propose to evaluate grounded Neural Language models that can perform compositional and spatial reasoning. Neural Language models (LM) have shown impressive capabilities on many NLP tasks but, despite their success, they have been criticized for their lack of meaning. Vision-and-Language models (VLM), trained jointly on text and image data, have been offered as a response to such criticisms, but recent work has shown that these models struggle to ground spatial concepts properly. In the project, we evaluate state-of-the-art pre-trained and fine-tuned VLMs to understand their grounding level on compositional and spatial reasoning. We also propose a variety of methods to create synthetic datasets specially focused on compositional reasoning. We managed to accomplish all the objectives of this work. First, we improved the state-of-the-art in compositional reasoning. Next, we performed some zero-shot experiments on spatial reasoning. Finally, we explored three alternatives for synthetic dataset creation: text-to-image generation, image captioning and image retrieval. Code is released at https://github.com/juletx/spatial-reasoning and models are released at https://huggingface.co/juletxara.