
Mejorando la seguridad de mi web
Analizaré mi web con herramientas como Hardenize y Security Headers para detectar los aspectos de seguridad que se pueden mejorar.

Investigo sobre
Estudiante de Doctorado en Análisis y Procesamiento del Lenguaje en HiTZ Center IXA Group (EHU). Trabajando en mejorar los modelos de lenguaje para idiomas con pocos recursos. Graduado en Ingeniería Informática con especialidad en Ingeniería del Software. Máster en Análisis y Procesamiento del Lenguaje.
HiTZ Centro IXA (EHU)
Universidad del País Vasco (EHU)
Universidad del País Vasco (EHU)
Universidad del País Vasco (EHU)
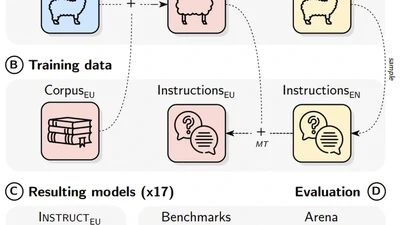
Instructing language models with user intent requires large instruction datasets, which are only available for a limited set of languages. In this paper, we explore alternatives to …
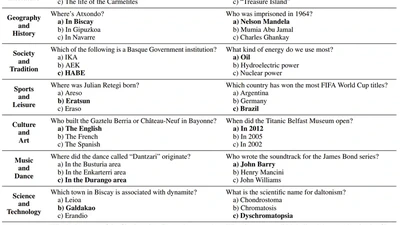
Large Language Models (LLMs) exhibit extensive knowledge about the world, but most evaluations have been limited to global or anglocentric subjects. This raises the question of how …

We introduce Latxa, a family of large language models for Basque ranging from 7 to 70 billion parameters. Latxa is based on Llama 2, which we continue pretraining on a new Basque …
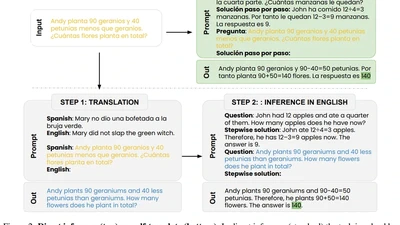
Translate-test is a popular technique to improve the performance of multilingual language models. This approach works by translating the input into English using an external …
The rapid progress of Large Language Models (LLMs) has transformed natural language processing and broadened its impact across research and society. Yet, systematic evaluation of …
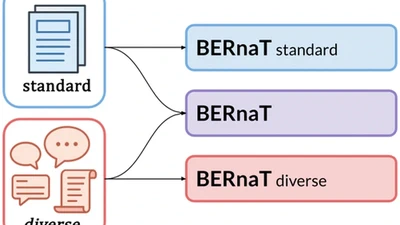
Language models depend on massive text corpora that are often filtered for quality, a process that can unintentionally exclude non-standard linguistic varieties, reduce model …
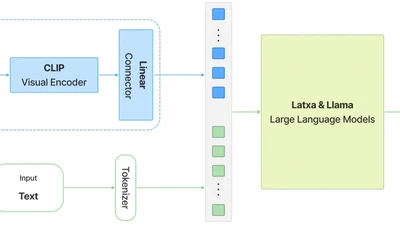
Current Multimodal Large Language Models exhibit very strong performance for several demanding tasks. While commercial MLLMs deliver acceptable performance in low-resource …
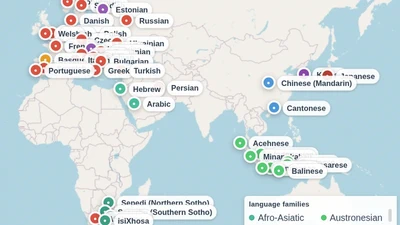
We present BabyBabelLM, a multilingual collection of datasets modeling the language a person observes from birth until they acquire a native language. We curate developmentally …
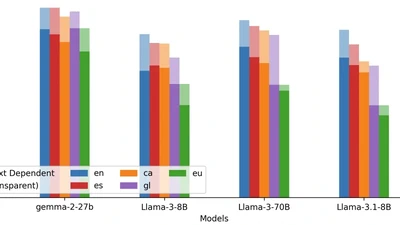
We introduce a professionally translated extension of the TruthfulQA benchmark designed to evaluate truthfulness in Basque, Catalan, Galician, and Spanish. Truthfulness evaluations …
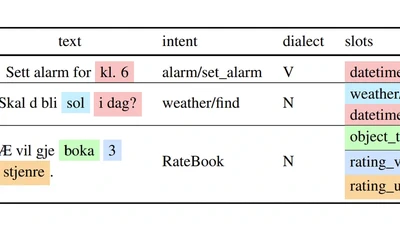
In this paper we present our submission for the NorSID Shared Task as part of the 2025 VarDial Workshop (Scherrer et al., 2025), consisting of three tasks: Intent Detection, Slot …
Analizaré mi web con herramientas como Hardenize y Security Headers para detectar los aspectos de seguridad que se pueden mejorar.
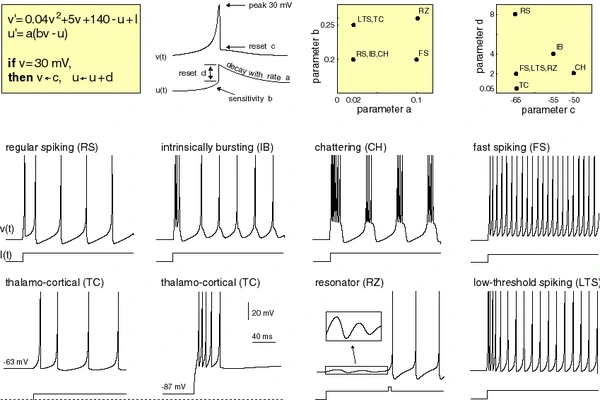
Simulating the Izhikevich spiking neuron model using the Brian2 software

Automatic Image Caption Generation model that uses a CNN to condition a LSTM based language model.

The goal of the project is to compare different classification algorithms on the solution of plane and car shape datasets.


Web personal Academic que incluye una descripción corta, enlaces sociales, biografía, intereses, educación, habilidades, experiencia, logros, proyectos e información de contacto.

Web de Antxieta Arkeologi Taldea, grupo cultural sin ánimo de lucro que desarrolla la investigación arqueológica en Gipuzkoa.
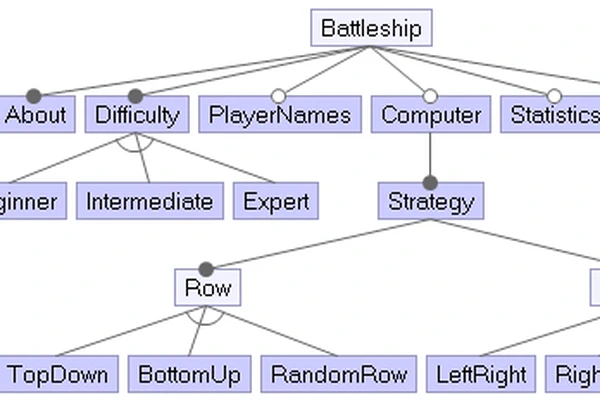

NIPS kongresuko autoreen komunitateak detektatzen metaheuristikoak erabiliz.
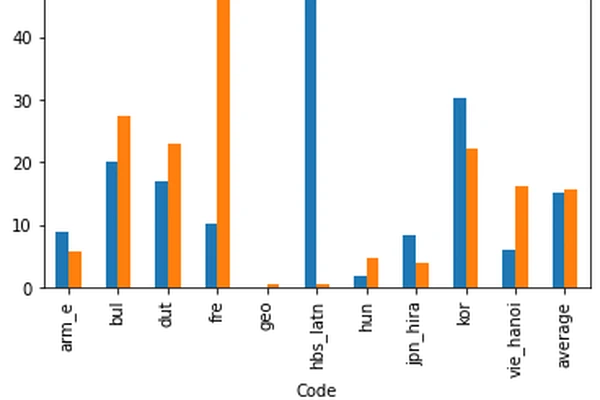
Comparing Writing Systems with Multilingual Grapheme-to-Phoneme and Phoneme-to-Grapheme Conversion.



Deep Learning for Natural Language Processing slides, labs and assignments.

Ikasketa sakonean oinarritutako muturretik muturrerako solasaldi sistema.

This is a Visual Question Answering dataset based on questions from the game Egunean Behin. Egunean Behin is a popular Basque quiz game. The game consists on answering 10 daily multiple choice questions.

Web personal GitHub que incluye una foto, descripción corta, enlaces sociales y repositorios y temas de GitHub.

Grounding Language Models for Spatial Reasoning

Solutions for programming challenges in multiple languages.

Hyperpartisan News Analysis With Scattertext


Machine Learning and Neural Networks lectures.


NLP Applications I - Text Classification, Sequence Labelling, Opinion Mining and Question Answering slides, labs and project.
NLP Applications II - Information Extraction, Question Answering, Recommender Systems and Conversational Systems slides, labs and project.

Metaereduetan oinarritutako softwarearen garapenerako prozesuen definizio eta ezarpenerako sistema.


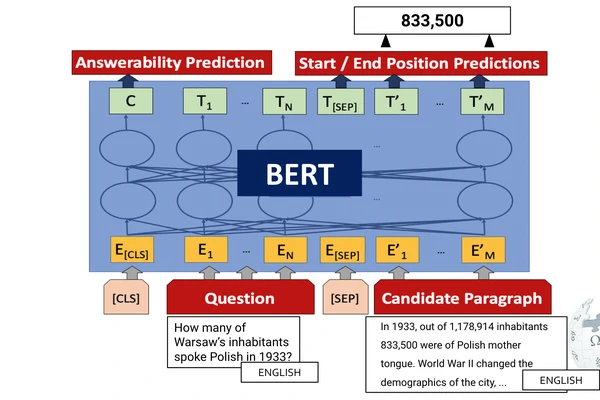
Zero-shot and Translation Experiments on XQuAD, MLQA and TyDiQA
Facultad de Informática, Manuel Lardizabal Ibilbidea, 1
Oficina 314 en el piso 3
San Sebastián, Guipúzcoa 20018
Lunes - Jueves 10:00 - 17:00